


A backpropagation algoritmus
Ez az az algoritmus, amelynek bevezetése lehetővé tette a hálózatok effektív tanítását és ezzel együtt elindította a deep learning világhódítását.A backpropagation algoritmust először összetett függvények automatikus differenciálásához fejlesztették ki, a neurális hálózatok tanítása során való használata Rumelhart, Hinton és Williams cikkének hatására vált népszerűvé.
Automatikus differenciálás visszafelé
Az automatikus differenciálás visszafelé algoritmus a láncszabály használatával lépésről lépésre számítja ki egy összetett kifejezés parciális deriváltjainak értékét. Egy többváltozós kifejezés egyik változójára vett parciális deriváltjának az értéke megadja a kifejezés értékének a változásának az arányát az adott változó értékenék változásához képest, miközben a többi változó értéke változatlan marad.Ez az algoritmus sokkal egyszerűbben leprogramozható és hatékonyabb, mint a szimbolikus differenciálás. (A szimbolikus differenciálás az, ahogyan papíron is legtöbbször deriválunk, vagyis meg kell lennie hozzá egy teljes matematikai kifejezésnek, amiből a deriválás egyes szabályait alkalmazva, majd egyszerűsítve megkapjuk a kifejezés deriváltját, amibe konkrét értékeket behelyettesítve számoljuk ki annak értékét.)
Vegyük példának a következő függvényt: \(f(x) = 0.5x + 0.2\)
Célunk, hogy kiszámítsuk \(\frac{f(x)}{dx}\)-et.
Az algoritmus működésének megértéséhez először vázoljuk fel a számítási gráfot:
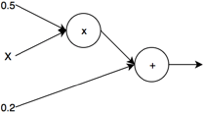

A gráfban két csomópont, node található. Egyik a szorzás, másik az összeadás műveletét végzi el. \(x = 2\) esetén a számítás a következő képpen zajlik:
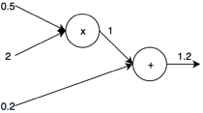

Az előrefelé haladó számítás elvégzése után minden node-nak tudni fogjuk a bemeneti és kimeneti értékeit. Ekkor következik a visszafelé irányuló rész, a \(x\)-re nézett derivált értékének kiszámítása \(x=2\) helyen. Ez a derivált érték értelmezhető úgy, hogyha \(x = 2\) helyen az \(x\) értékét megváltoztatjuk, akkor az mekkora változást fog jelenteni a végeredményben.
Haladjunk tehát visszafelé, lépésről lépésre, node-ról node-ra. Az összeadás node-al kezdünk.
Ennek a node-nak 1 és 0.2 a két inputja és 1.2 az outputja. Látható, ha a node bármely inputját megváltoztatjuk, az ugyanannyi változást fog jelenteni az outputban (1-nek a 2-re növelése esetén az output is eggyel lesz több, 2.2). Ezért a függvény szorzás node outputjára nézett deriváltjának értéke 1. Most következik a szorzás node. Nézzük meg, mennyit változik ennek a node-nak a kimenete, ha x-et módosítjuk. Növeljük \(x\)-et 1-el, \(x = 3\) esetén a kimenet \(3 \cdot 0.5 = 1.5\) lesz. Ez a változáshoz képest \(0.5\)-szörös növekedés természetesen a szorzás miatt.
Most már látható, hogy összeadás esetében a derivált értéke 1, míg szorzás esetében az output egyik inputjára vett deriváltjának értéke meg fog egyezni a másik input értékével. Így minden node ki tudja számolni a saját outputjának a saját inputjaira nézett deriváltjainak értékeit. Most ezekből a köztes derivált értékekből kellene hozzájutnunk a számítási gráf végső outputjának az egyes bemenetekre nézett derivált értékeihez.
Ha tudjuk azt, hogy az \(x\)-nek a változására hányszorosára változik a szorzás node outputja, és tudjuk azt, hogy a szorzás node outputjának változására annak hányszorosára változik a végső output, akkor magától értetődően a kettő szorzatából megkapjuk, hogy az \(x\) változására mennyit fog változni a végső kimenet. Ez gyakorlatilag a deriválás láncszabálya.
Formálisan:
\(\frac{dx}{dz} = \frac{dx}{dy} \cdot \frac{dy}{dz}\)
Alkalmazása a neurális hálózatok esetében
Neurális hálózatok esetében a gradient descent algoritmus során szükségünk van a hiba függvénynek a hálózat minden egyes paraméterére (súlyokra és torzításokra) vett parciális deriváltjának értékére, ezen értékek kiszámítására használjuk az automatikus differenciálást. A backpropagationt tehát gradient descent visszafelé történő automatikus differenciálással.Az előbbi számítási gráf megegyezik egy lineáris neuron számítási gráfjával, ahol 0.5 a \(w\) vagyis a súly, 2 az \(x\) vagyis a bemenet és 0.2 pedig a \(b\) azaz a torzítás értéke.
Egy sigmoid neuron esetében még ehez jön a sigmoid függvény alkalmazása:
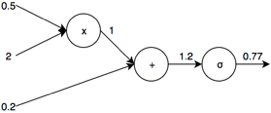

Ezután ezt a kimeneti értéket vagy továbbítjuk a következő réteg neuronjai felé, vagy összehasonlítjuk a tényleges várt kimenettel és kiszámoljuk az eltérést, vagyis a hiba nagyságát valamely hibafüggvény segítségével, majd a hibafüggvény deriváltjából megkapjuk, hogy ez mennyiben vett részt a hiba kialakításában. Most mivel egyetlen neuronunk van, vegyük az utóbbi eshetőséget.
A négyzetes hibafüggvény:
\(C_{SE}(y_{pred}, y) = \frac{1}{2}(y_{pred} – y)^2\)
\(y_{pred}\) a jósolt érték (jelen esetben \(a\)), \(y\) pedig a várt érték.A deriváltja:
\(C_{SE}'(y_{pred}, y) = y_{pred} – y\)
Tegyük fel, hogy az \(x = 2\)-höz tartozó \(y = 0.5\).Ekkor a hiba közelítőleg 0.036 lesz, a derivált értéke pedig 0.269. Ez az érték a hibafüggvénynek a neuron kimenetére vett deriváltjának értéke. Jelöljük a hibafüggvényt C-vel, ekkor:
\(\frac{\partial C}{\partial a} = 0.269\)
Egy több neuronból álló hálózatban ezt az értéket a következő réteg vagy a kimenet felől minden egyes neuron megkapja. Az ő egyik feladatuk, hogy kiszámolják a súlyaiknak és a torzításuknak a hibafüggvényre nézett deriváltját ebből a megkapott értékből, a másik feladatuk pedig, hogy kiszámolják a hibafüggvénynek az előző réteg aktivációs értékeire vett deriváltjának az értékeit és továbbadják azokat az előző réteg neuronjaina, hogy ők is el tudják végezni ugyan így a feladataikat.Ahhoz, hogy példa neuronunk ki tudja számolni az előbb említett deriváltak értékeit, első lépésként a \(\frac{\partial C}{\partial z}\) értéket kell kiszámolni, vagyis a köztes \(z\) értékre vett parciális derivált értékét. Minden neuron tudja hogy az ő aktivációs függvényének mi a hatása a kimenetére. Jelen esetben a szigmoid függvény deriváltja:
\(\sigma'(x) = \sigma(x) \cdot (1 – \sigma(x))\)
Ezzel kiszámolható a \(\frac{\partial a}{\partial z}\), aminek segítségével pedig \(\frac{\partial C}{\partial z}\) a láncszabály alkalmazásával:\(\frac{\partial a}{\partial z} = sigmoid'(z) = 0.178\)
\(\frac{\partial C}{\partial z} = \frac{\partial C}{\partial a} \cdot \frac{\partial a}{\partial z} = 0.048\)
Ezt a \(\frac{\partial C}{\partial z}\) értéket szokás a neuron hibájának nevezni és \(\delta\)-val jelölni.Most számoljuk ki a súlyra nézett derivált értékét:
\(\frac{\partial z}{\partial w} = 2\)
\(\frac{\partial C}{\partial w} = \frac{\partial C}{\partial z} \cdot \frac{\partial z}{\partial w} = 0.96\)
A torzítás egységre vett derivált pedig megegyezik \(\frac{\partial C}{\partial z}\)-vel, mivel csak egy összeadásnak a résztvevője:\(\frac{\partial C}{\partial b} = 0.048\)
Most már tudjuk ezen neuron minden paraméterére a meredekséget. Ha nem egy első réteg beli neuronról lenne szó folytatni kellene az algoritmust ugyan ezen számítások elvégzésével az előző rétegben mindaddig amíg az összes rétegen végig nem érünk, ahogy azt a következő teljes példában látni fogjuk. Ahhoz viszont az előző réteg neuronjainak szükségük van a hibafüggvénynek az ő kimenetükre nézett deriváltjának az értékére. Mint most is láthattuk a kimeneti rétegbeli neuron ezt egyenesen a hibafüggvény deriváltjából kapja.Egy teljes működő példa Pythonban
A példa kódjának futtatásához a szükség van a numpy és a scikit-learn csomagokra.Ahogy az az előadásomban is volt, mátrixokat és mátrix műveleteket fogunk használni. Ezek azért előnyösek, mert vektorizált műveletek, sokkal gyorsabbak mint ha ciklusokkal implementálnánk ugyanazokat a számításokat.Eddig a cikkben csak egyetlen, egy inputtal rendelkező neuronnal foglalkoztunk az algoritmus könyebb megérthetősége és követhetősége érdekében.
Az előadáson bemutatott problémára fogunk alkalmazni egy neurális hálót, vagyis házak árának a megjóslására az átlagtulajdonságaik alapján. A California housing dataset Kalifornia egyes részein lévő házak átlagtulajdonságait és átlagárait tartalmazza.

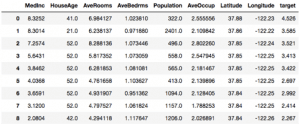
Kezdjük a szükséges dolgok importálásával:
|
1 2 3 |
import numpy as np from sklearn.datasets import fetch_california_housing from sklearn.preprocessing import StandardScaler |
|
1 2 3 4 5 6 7 8 9 10 11 |
np.random.seed(21) <br> <br> housing = fetch_california_housing() <br> <br> X = housing["data"] shuffled_indices = np.random.permutation(np.arange(X.shape[0])) X_shuffled = X[shuffled_indices] X_test = X[19000:] X = X[:19000] |
|
1 2 3 4 5 |
scaler = StandardScaler() X = scaler.fit_transform(X) X_test = scaler.transform(X_test) X = X.T X_test = X_test.T |
|
1 2 3 4 |
y = housing["target"].reshape(1, -1) y_shuffled = y[:, shuffled_indices] y_test = y[:, 19000:] y = y[:, :19000] |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
def mse(y_predicted, y): return 1 / (2 * y.shape[1]) * np.power(y_predicted - y, 2).sum() <br> <br> def mse_prime(y_predicted, y): return y_predicted - y <br> <br> def relu(x): return x * np.float64(x > 0) <br> <br> def relu_prime(x): return np.float64(x > 0) |


Forrás: http://neuralnetworksanddeeplearning.com/
Ahogy azt az ábra is mutatja a harmadik réteg második neuronját a második réteg negyedik neuronjával összekötő kapcsolat súlyát a harmadik réteg súlymátrixa fogja tartalmazni a neuron harmadik rétegbeli pozíciójának megfelelő sorban és az előző rétegbeli neuron pozíciójának megfelelő oszlopban. Hozzuk tehát létre a szükséges mátrixokat, és inicializáljuk a súlyokat kicsi random értékekre a szimmetria megtörése céljából:|
1 2 3 4 5 6 7 8 9 10 |
m = X.shape[1] n = X.shape[0] <br> <br> n1 = 5 n2 = 1 w1 = np.random.randn(n1, n) * .01 w2 = np.random.randn(n2, n1) * .01 b1 = np.zeros((n1, 1)) b2 = np.zeros((n2, 1)) |
|
1 2 3 4 5 |
num_epochs = 1000 learning_rate = 0.1 <br> <br> for epoch in range(0, num_epochs): |
|
1 2 |
z1 = w1.dot(X) + b1 a1 = relu(z1) |
|
1 2 |
z2 = w2.dot(a1) + b2 a2 = z2 |
|
1 2 3 4 |
cost = mse(a2, y) if epoch % 100 == 0: print(cost) |
\(\frac{\partial C}{\partial a^2_j} = a^2_j – y_j\)
|
1 2 3 |
dcost_da2 = mse_prime(a2, y) da2_dz2 = 1 dcost_dz2 = np.multiply(dcost_da2, da2_dz2) |
\(\frac{\partial z^2_j}{\partial a^1_k} = w^2_{jk}\)
|
1 |
dz2_da1 = w2 |
\(\frac{\partial C}{\partial a^1_j} = \sum_k \frac{\partial C}{\partial z^2_k} \frac{\partial z^2_k}{\partial a^1_j} \)
|
1 |
dcost_da1 = dz2_da1.T.dot(dcost_dz2) |
\(\frac{\partial a^1_j}{\partial z^1_j} = relu'(z^1_j)\)
\(\delta^1_j = \frac{\partial C}{\partial a^1_j}\frac{\partial a^1_j}{\partial z^1_j}\)
|
1 2 |
da1_dz1 = relu_prime(z1) dcost_dz1 = np.multiply(dcost_da1, da1_dz1) |
\(\frac{\partial z^l_j}{\partial w^l_{jk}} = a^{l – 1}_k \)
\(\frac{\partial C}{\partial w^l_{jk}} = \frac{\partial C}{\partial z^l_j} \frac{\partial z^l_j}{\partial w^l_{jk}}\)
\(\frac{\partial C}{\partial b^l_j} = \frac{\partial C}{\partial z^l_j} = \delta^l_j\)
|
1 2 3 4 5 6 7 |
dz2_dw2 = a1 dcost_dw2 = 1 / m * dcost_dz2.dot(dz2_dw2.T) dcost_db2 = 1 / m * dcost_dz2.sum(1, keepdims=True) dz1_dw1 = X dcost_dw1 = 1 / m * dcost_dz1.dot(dz1_dw1.T) dcost_db1 = 1 / m * dcost_dz1.sum(1, keepdims=True) |
|
1 2 3 4 5 |
w2 = w2 - learning_rate * dcost_dw2 b2 = b2 - learning_rate * dcost_db2 w1 = w1 - learning_rate * dcost_dw1 b1 = b1 - learning_rate * dcost_db1 |
|
1 2 3 4 5 6 |
z1 = w1.dot(X_test) + b1 a1 = relu(z1) z2 = w2.dot(a1) + b2 a2 = z2 print("test error:", mse(a2, y_test)) |
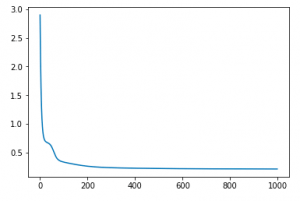

A hálózat forráskodja megtalálható az alábbi IPython notebookban: https://github.com/ViktorSimko/bnh/blob/master/introduction_to_neural_networks.ipynb
A cikk elkészítéséhez a következő források voltak segítségemre: